CECI N´EST PAS UNE PIPE: UNA REFLEXIÓN SOBRE LA RELACIÓN ENTRE LAS PALABRAS Y LAS IMÁGENES EN LA INTELIGENCIA ARTIFICIAL GENERATIVA Y SU USO EN ENSEÑANZAS ARTÍSTICAS
CECI N´EST PAS UNE PIPE: A REFLECTION ON THE RELATIONSHIP BETWEEN WORDS AND IMAGES IN GENERATIVE ARTIFICIAL INTELLIGENCE AND ITS USE IN ARTISTIC EDUCATION.
Concha García González
Universidad Complutense de Madrid
DOI: 10.33732/ASRI.6588
Recibido: (22 01 2024)
Aceptado: (23 07 2024)
Cómo citar este artículo
García González, Concha. (2024). Ceci n´est pas une pipe: Una reflexión sobre la relación entre las palabras y las imágenes en la Inteligencia Artificial. ASRI. Arte y Sociedad. Revista de investigación en Arte y Humanidades Digitales., (25), 105-118.
https://doi.org/10.337332/ASRI.6588
Resumen
Estas páginas narran una práctica realizada a lo largo de varias sesiones en el contexto de la asignatura Tecnologías Digitales, que imparto en el ámbito universitario del Grado en Arte, así como las reflexiones surgidas a la luz de los resultados de esta. En el contexto de la realización del proyecto final de investigación personal que se realiza en la mencionada asignatura, se proponía una pequeña investigación práctica en sistemas de Inteligencia Artificial -en adelante IA- generativa del tipo texto-imagen -text to images-, así como una invitación al alumnado a utilizar los resultados obtenidos en la práctica para concebir y crear materiales de trabajo y realizar dicho proyecto.
Se exhortaba a reflexionar de forma crítica sobre la relación entre los textos introducidos y las imágenes generadas en particular, y por extensión, sobre la relación entre las imágenes y las palabras que presuntamente las describen. Estas páginas relatan el procedimiento utilizado, algunas reflexiones y el análisis de un caso práctico del trabajo de una de las alumnas.
Palabras clave
Inteligencia Artificial Generativa, práctica artística, tecnologías digitales, relación texto- imagen.
Abstract
These pages narrate a practice carried out during several sessions in the context of the subject Digital Technologies, which I teach at the university level of the Bachelor of Arts, as well as the reflections arising in the light of its results. In the context of the final personal research project carried out in the afore mentioned subject, small practical research in Artificial Intelligence generative systems was proposed (henceforth IA) of the type of text-image (text to images), as well as an invitation to students to use the results obtained in their research to conceive and create working materials and carry out their project. They were called for a critical reflection on the relationship between the texts introduced and the images generated and by extension, between the images and the words allegedly describing them. These pages relate the procedure used, some reflections and the analysis of a case study of the work of one of the students.
Keywords
Generative Artificial Intelligence, artistic practice, digital technologies, text-to -image relationship.
Introducción
La Figura 1 es una imagen generada en DALL·E 2 a partir de la introducción del texto “This is not a pipe”, haciendo referencia a la traducción al inglés del título de la obra homónima de Magritte, Ceci n´est pas une pipe, que da título a estas reflexiones. Esta obra, cuestiona las complejas relaciones entre las palabras, es decir, el lenguaje y las imágenes, así como entre la representación y el propio objeto representado. La imagen obtenida en DALL·E 2 resume de forma muy explícita -y alegórica, como se explica a continuación-, el breve trabajo investigador recogido en estas páginas acerca del uso, por parte de estudiantes de Facultades de Bellas Artes, de las Inteligencias Artificiales Generativas -AI- del tipo neural network para realizar sus propios proyectos creativos. Ya en 2020, el artista Trevor Paglen, (2019) en su exposición From Apple to anomaly en el Barbican Centre, colocó como imagen introductoria el cuadro de Magritte, Ceci n´est pas une pomme, haciéndose la pregunta: para mí, ¿qué es una manzana?, y por extensión, ¿qué es la representación? Esta imagen, se convertía, según Paglen, en una alegoría de la constatación de que las representaciones siempre son relacionales y están basadas en el consenso, que puede variar: una manzana puede simbolizar el pecado en determinados contextos. En nuestro caso, en el que hemos utilizado el título de otro cuadro del pintor, Ceci n´est pas une pipe traducido al inglés por el idioma de entrenamiento de las redes neuronales1, además aparece el componente polisémico de la palabra “pipe” en inglés2. Podemos decir, en suma, que, al carácter relacional de todo concepto por sus significados asociados, se añade el componente polisémico que convierte en paradójica la representación obtenida, algo así como la constatación del eterno malentendido comunicativo.
Figura 1. Imagen generada en DALL-E a partir de sucesivas inserciones del texto This is not a pipe. 2023.

Desde hace años imparto la asignatura Tecnologías Digitales en el contexto universitario de Grado en Artes. Esta asignatura tiene como objetivo iniciar a los alumnos en el uso de tecnologías básicas del ámbito de la manipulación de la imagen digital. La realidad es que existe una importante proporción de estudiantes que, impulsados por una idea tradicional del arte, razonan que sienten aversión por la máquina, y no conciben su obra artística realizada con estos medios, sintiendo predilección por los procesos materiales tradicionalmente asociados al arte. Nuestro primer objetivo desde la asignatura es, por un lado, que se reflexione sobre la larga tradición tecnológica indisolublemente unida a la condición humana, pues nuestro funcionamiento como especie ha estado siempre basado en la creación y uso de algoritmos, sean estos científicos, como el ADN o culturales, entendidos como instrucciones de comportamiento que legitiman en las diversas culturas sus modos de hacer (Zylinska, 2020, p.107). Además, se persigue que introduzcan en sus procesos de trabajo ciertos modos de pensar y entender el arte que derivan del uso de las tecnologías y son exclusivos de ellas, y que lo hagan sin incurrir en un instrumentalismo acrítico.
Uno de los problemas que se planteó por primera vez en el curso 2022-23 es el uso de las Inteligencias Artificiales Generativas basadas en neural network, concretamente del tipo llamado Diffusion models, como DALL·E 2, que crea imágenes a partir de líneas de texto descriptivas. Esto significa que realiza una traducción entre contenidos de diferentes medios; de palabra -o lenguaje natural- a imagen. El tipo de IA al que pertenecen se llama neural network porque sus capacidades están distribuidas a lo largo de miles de millones de redes neuronales artificiales, simulando la complejidad de funcionamiento del cerebro humano. Son generativas porque el sistema crea nuevos contenidos, en este caso nuevas imágenes, a partir de los datos con los que ha sido entrenado. Además, utilizan la llamada técnica de difusión, que consiste en el entrenamiento de redes neuronales artificiales para revertir el proceso de adición de ruido -noise- a una imagen, y transformar un conjunto de píxeles en una imagen que concuerde con el texto proporcionado. Podemos resumir su funcionamiento diciendo que, introduciendo en un cuadro de texto una descripción de lo que queremos sea representado, el sistema genera una imagen única que recoge, según el conjunto de datos almacenados para su entrenamiento, las características descritas por el texto.
Los objetivos de esta práctica, utilizando este tipo de sistemas, han sido:
Propiciar un debate acerca de la relación del arte y los artistas con estas herramientas.
Reflexionar de forma crítica sobre la relación entre los conceptos y las imágenes en estos sistemas.
Lanzar una serie de preguntas, tales como: ¿de qué manera “ven” las máquinas el mundo?, ¿se trata realmente de un “ver” ?, ¿quién es el/la/lo que ve en esa visión?, ¿es una visión que no requiere al sujeto que tradicionalmente veía?, ¿esa visión puede incluirnos?, ¿a que “nosotros” nos referimos cuando utilizamos sistemas de IA y buscamos sentirnos interpelados o conmovidos por ellos?, ¿nos incluye, nos expulsa?
Su uso, como comentábamos anteriormente, se ha introducido en la parte final de la asignatura en 2023, y se ha enfocado como un apartado preliminar del último proyecto del curso, consistente, a grandes rasgos, -y sin entrar en detalles de la descripción, pues excede los límites de estas páginas- en la representación de un espacio imaginario. El enunciado, grosso modo, decía así:
Realización de una secuencia de imágenes en forma de ensayo visual multiformato que recoge una investigación acerca de un espacio. Este espacio investigado puede ser real o inventado; puede ser un espacio formado por varios, cuya unidad encontramos reunida bajo un concepto, como, por ejemplo, el espacio de lo prohibido, el espacio onírico, el espacio de la infancia, etc. (García, 2023).
Se añadían a continuación conceptos básicos para su desarrollo, como el concepto de Atlas, entendido como forma visual del saber o como colección de cosas singulares y heterogéneas cuya afinidad produce un saber extraño e infinito, abierto. (Didi- Huberman, 2010).
¿Puede, nos preguntamos, un atlas de nuestra época dejar fuera a los sistemas de IA?, ¿no es acaso, cada sistema de IA un atlas contemporáneo, por el proceso de creación de taxonomía subyacente, por el ordenamiento que realiza de las bases de datos introducidas para su entrenamiento?
Metodología
2.1. Precedentes
La IA ha sido explicada, en el contexto de la asignatura, como continuación de una larga tradición de formas de hacer arte a partir de la acumulación de materiales de origen diverso, en este caso, de imágenes. Durante semanas hemos trabajado, de forma teórica y práctica, estas relaciones. Desde los retratos compuestos realizados por Francis Galton (1879) -en contextos alejados del arte, pero que sirvieron de referencia para posteriores trabajos artísticos como los de Nancy Burson-, los collages experimentales de John Heartfield y Hanna Hoch, hasta a la gran cantidad de artistas contemporáneos que desarrollan estéticas y poéticas a partir de bases de datos, en la asignatura se ilustra el concepto de base de datos como forma simbólica [Database as a symbolic form] utilizado por una gran parte del arte contemporáneo. Expuesto por Lev Manovich en su artículo homónimo de 1998 (Manovich, 1998), a partir del análisis del historiador de arte Ervin Panofsky (2003) de la perspectiva lineal como forma simbólica, sostiene que en la era de los ordenadores es “una nueva manera de estructurar nuestra experiencia de nosotros y del mundo” (Manovich, 1998).
Siguiendo a Manovich y Arielli (2023), consideramos que estos sistemas de IA constituyen un nuevo método de lectura de las bases de datos culturales, permitiendo crear también nuevas narrativas y nuevos atlas. Desde este marco teórico se realizó esta práctica.
2.2. Enunciado
Como punto de partida para la investigación, se facilitó una serie de instrucciones. Se invitó a los participantes a introducir una línea de texto descriptiva de al menos cuatro palabras, relacionada con el enfoque particular que cada cual quisiera dar al tema planteado, "espacio imaginario". Esta línea de texto debía ser introducida en los diferentes sistemas de IA propuestos, siempre en inglés, por ser este el idioma de entrenamiento de los sistemas propuestos: Starry AI; Wombo Dream by Wombo; Nightcafe; DALL·E mini, que ha migrado a CRAYON; DALL-E 2; Deep AI; Deep dream Generator; Midjourney; Pixray; Artbreeder. Se pedía elegir y recopilar los ‘mejores’ resultados obtenidos, añadiendo además para cada sistema una puntuación, utilizando una escala del 1 al 5, calificando dos categorías: estética, siempre desde el punto de vista subjetivo y la fidelidad entre texto-imagen. Debía añadirse además un breve texto crítico sobre la opinión creada, a la luz de los resultados obtenidos, de estos sistemas en general o de alguno de ellos en particular. El resultado debía de ser presentado públicamente y comentado en clase. Esta primera parte permitió lanzar en el aula un debate interesante sobre, en primer lugar, la relación entre texto e imagen, determinante en estos sistemas de IA y, en segundo lugar, sobre la utilidad que los alumnos encontraban en su utilización con fines creativos.
Desarrollo
El primer problema se plateó a la hora de seguir las instrucciones “Introduce una línea de texto descriptiva…” pues desde el primer momento se hizo patente la imposibilidad de una definición que pueda acotar qué es un uso descriptivo del lenguaje, y la duda de si este carácter descriptivo puede extenderse o no a conceptos más abstractos e intangibles y de qué manera.
Para que una red neuronal aprenda y por tanto nos devuelva una respuesta, necesita ser entrenada con una gran cantidad de datos. Leemos, por ejemplo, que
para entrenar el modelo original de DALL-E, que contiene 12 mil millones de parámetros, se utilizó un conjunto de 250 millones de pares de texto-imagen (públicamente disponibles en Internet). Este conjunto de datos es una mezcla de varios datasets previos compuesto por tres fuentes principales (Alija, 2023).3
Esos datos tienen que estar etiquetados [tagged], lo que quiere decir que a las imágenes utilizadas para el entrenamiento hay que asociarles determinados nombres y conceptos: palabras, en definitiva. Por ello se denomina aprendizaje supervisado [Supervised learning]. Estos sistemas devuelven respuestas, en este caso en forma de imágenes, es decir, “traducen” de un lenguaje a otro, proporcionando la sensación de que esas asociaciones generadas fueran las únicas posibles. Parecería que existiese una relación fija e inamovible entre conceptos e imágenes: una correspondencia universal. Pero tal cosa no existe, como desarrollan Kate Crawford y Trevor Paglen en su análisis de la “manera de ver” de los sistemas de inteligencia artificial (Crawford y Paglen, 2019) y (Cowan, 2023). Esta asunción hace que, aparentemente, desaparezca de golpe, por el mero acto de etiquetar, la complejidad de la red de significados que pueden relacionar una imagen y un concepto
3.1. Chat GPT
Preocupados por esta relación entre las palabras y las imágenes, decidimos indagar acerca de la “opinión” que el ChatGPT tenía sobre esta relación. Utilizamos opinión en sentido figurado, pues como François Chollet, investigadora de IA en Google y responsable de Keras, una herramienta utilizada para el aprendizaje profundo [Deep learning] escribió recientemente, “…un modelo de [aprendizaje profundo] es excelente reproduciendo la semejanza visual local (en qué se ajusta), sin embargo, no tiene comprensión de las partes y su organización.” (Kremer, 2022). Un sistema AI no entiende las relaciones entre las partes y el todo, por lo que no puede generar una opinión. Alguien externo al sistema introduce el significado y la interpretación, o lo que es lo mismo, las bases de la ‘opinión’. Foucault nos recordaba “… existe en toda cultura, entre el uso de lo que pudiéramos llamar los códigos ordenadores y las reflexiones sobre orden, una experiencia desnuda del orden y sin modos de ser” (1989, p.6). En la base que entrena las redes neuronales existe una idea de orden que no es universal, y que es la que ha puesto los cimientos de la cultura occidental. Para realizar la exposición anteriormente mencionada, Trevor Paglen (2019) utilizó el set de entrenamiento de sistemas de IA ImageNet (2009), publicado en 2009 y creado por investigadores de la universidad de Stanford. El artista afirma que una mirada más cercana a este set de entrenamiento nos muestra categorías de clasificación clasistas, racistas, homófobas, misóginas e incluso crueles. Sería interesante, a la luz de estas afirmaciones, elaborar una arqueología de los procesos de entrenamiento de las redes neuronales, y lanzar la pregunta de quién las entrena, las financia y con qué finalidad. Hay que recordar que “gran parte de la investigación artística en torno a la IA es facilitada y patrocinada por los principales actores dentro de lo que se conoce como capitalismo de plataformas: Google, Amazon, Facebook”. (Zylinska, 2020, p.75).
Figura 2. Captura de pantalla de la conversación mencionada mantenida con el ChatGPT. 2023. Elaboración propia.
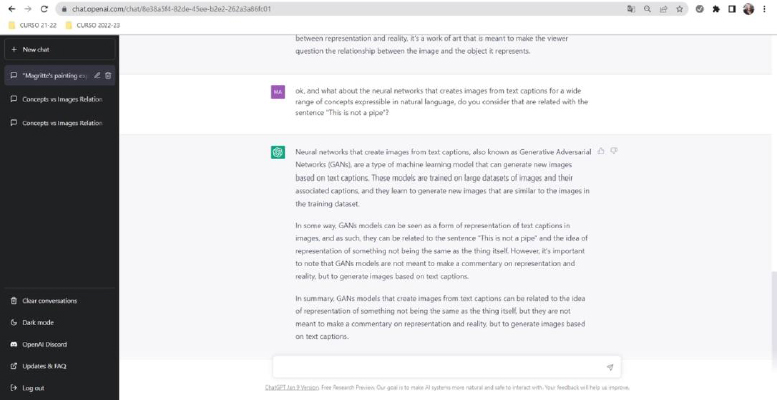
Interrogado el ChatGPT sobre la relación existente entre palabras e imágenes, la respuesta obtenida fue que, aunque el sistema reconoce que no existe una relación inamovible entre texto e imágenes y que
varían según el contexto, la cultura y las perspectivas individuales de las personas que los interpretan, añadiendo que el significado de un concepto o imagen puede cambiar con el tiempo, o estar abierto a la interpretación. Es un proceso de asociación de etiquetas o palabras clave con una imagen para describir su contenido o contexto” (OpenAI, 2023).
Así pues se puede etiquetar imágenes y la clave está en la acción de describir y su significado, atribuyéndole una presunta objetividad de la que, por supuesto, carece.
El acto descriptivo es subjetivo y está fuertemente influido por la experiencia, cultura y contexto de quien lo realiza: los algoritmos culturales antes mencionados que legitiman, en las diversas culturas, sus modos de hacer. Pasado a preguntar después por la relación entre el etiquetado de imágenes y las palabras This is not a pipe4, del título del cuadro de Magritte, obtenemos una serie de respuestas de las que adjuntamos la conclusión:
los modelos GAN que crean imágenes a partir de texto pueden estar relacionados con la idea de representación de algo que no es lo mismo que la propia cosa, pero no están destinados a hacer un comentario sobre representación y realidad, sino a generar imágenes basadas en títulos de texto.”(OpenAI, 2023).
Es decir, que no encontró ninguna relación entre ambas afirmaciones, porque les atribuyó objetivos diferentes. Asombra la simplicidad con la que el sistema ha sido “enseñado” a contestar acerca de la célebre frase de Magritte This is not a pipe, afirmando que la representación no es lo mismo que la cosa en sí, entendiendo como representación también el propio texto que por medio del lenguaje define el objeto, pero haciendo caso omiso al resto de implicaciones y significados que ya el texto de Michel Foucault (1989) analizó largamente. Para él, lo que Magritte hace con este texto al colorarlo debajo de la representación de una pipa es una diablura, “un caligrama secretamente constituido y luego deshecho con cuidado” (p.32). El caligrama, –continuaba Foucault–, “pretende borrar lúdicamente las más viejas oposiciones de nuestra civilización alfabética: mostrar y nombrar; figurar y decir; reproducir y articular; imitar y significar; mirar y leer.” (p. 32). ¿Podemos considerar, pues, a las inteligencias artificiales Generativas del tipo red neuronal [neural network] como DALL·E 2, que crean imágenes a partir de líneas de texto descriptivas, creadoras de nuevos tipos de caligramas?
Sabemos ya hace tiempo, refiriéndonos al mundo del arte, que la relación de las palabras con las imágenes no es estable. Así citaba Foucault a Magritte cuando afirmaba que
entre las palabras y los objetos se pueden crear nuevas relaciones y precisar algunas características del lenguaje y los objetos generalmente ignorados en la vida cotidiana. Una palabra puede ocupar el lugar de un objeto en la realidad. Una imagen puede tomar el lugar de una palabra en una proposición. Y esto no implica en absoluto contradicción, ya que se refiere a la vez a la red inextricable de las imágenes y las palabras y a la ausencia de lugar común que pueda sostenerlas. (Foucault, 1989, p. 58).
No obstante, el etiquetado del ChatGPT asume que existen patrones formales objetivamente asociados a las esencias o a los conceptos enunciados; que conceptos abstractos como alegría o tristeza tienen su correlato visual. En definitiva, el etiquetado se olvida del hecho de que las bases de datos y su forma de estructurarse reflejan una visión del mundo y son “intervenciones políticas”, como afirman Crawford y Paglen (2019), que nunca pueden ser neutrales. No existe ningún punto de vista apolítico, neutral, objetivo, desde el que se pueda crear un sistema de IA y entrenarlo con datos, porque categorizar y etiquetar es una forma de política.
3.2. Uso de los sistemas de AI propuestos y debate
Una vez discutida esa imposibilidad de nombrar de forma objetiva, cada estudiante procedió a introducir el texto elegido en los sistemas propuestos.
De las opiniones recabadas en el debate generado sobre las imágenes devueltas por los sistemas de IA, destacamos que muchos resultados eran considerados banales: una mera invitación al entretenimiento y la diversión más que a una reflexión posterior: “un mero mar psicodélico de garabatos y risitas y no mucho más entremedias. Realmente arte como espectáculo.” (Zylinska, 2020, p. 76).
Algunos estudiantes destacaban los componentes estéticos de las imágenes obtenidas, pero los consideraban no referenciados, es decir, ahistóricos. A este respecto, abundaban los ejemplos de lo que Zylinska ha llamado “transferencia estilística” (p. 62), que bajo ningún concepto expande el campo del arte. Además, parte del alumnado sostenía que observaban un estilo “por defecto” en cada uno de los sistemas AI, y que, para escapar a este estilo, necesitaban afinar los términos de búsqueda y “guiarla”
-por medio del texto- hacia determinados colores, iluminación, según sus preferencias conceptuales o estéticas, y no cesaban hasta que el resultado les satisfacía.
Otros estudiantes se quejaban de la opacidad del sistema, que impedía entender los criterios de traducción de las palabras en imágenes. Dicho de otra manera, el sistema les impedía entender cómo “ven” las máquinas el mundo5, algo a lo que Zylinska se refiere como el agujero de la traducción, [translation gap] que considera epistemológico y ontológico (2020, p. 95). Esto favorece que la IA sea concebida como una caja negra. [black box] (p. 90).
Los estudiantes echaban de menos el acceso a sistemas de IA en los que ellos mismos pudieran controlar las imágenes que entrenan el sistema y su etiquetado, o incluso prescindir de la supervisión, de ahí que algunos decidieron introducir en los sistemas sus propias imágenes para que el procedimiento generativo crease a partir de ellas. Es destacable que, en general, se desató un espíritu crítico que les hacía afirmar que sólo con el uso rápido y directo de estos sistemas no podían sentirse interpelados por los resultados obtenidos6. Tampoco podían sentir como suyos los resultados obtenidos en colaboración con los sistemas de IA si no realizaban un trabajo de montaje y postproducción posterior.
Resultados: Análisis de caso
Para ilustrar el “agujero de la traducción” y el efecto de caja negra, analizaremos uno de los trabajos realizados por una de las alumnas, pues no disponemos de espacio para extendernos más. Se trata del trabajo de la alumna Celia González Cáceres, cuyas imágenes y proceso de trabajo publicamos con su permiso gracias a su generosidad. Destacamos este trabajo porque sirvió extraer conclusiones y algunas metodologías de uso.
La alumna definió el espacio que estaba interesada en desarrollar como “El espacio de la nostalgia por el futuro”. Al traducir este concepto al inglés, idioma de entrenamiento de los sistemas de IA, eligió el texto descriptivo Future nostalgia. Este es un concepto que parece estar relacionado con el de Hauntología, tal y como lo popularizó Mark Fisher (2012), a partir del término acuñado por Jacques Derrida (1995). Fisher distingue dos direcciones en la hauntología: la primera se refiere a lo que ya no es, pero aún es efectivo -es decir, lo que produce nostalgia- y la segunda se refiere a aquello que aún no ha ocurrido, pero que es efectivo de forma virtual en el momento presente. En este caso, estas dos direcciones temporales, pasada y futura, se unifican en la línea de texto descriptiva, reuniendo ambos conceptos.
En la primera búsqueda, observó que las imágenes que le eran devueltas se referían, en su gran mayoría, a coches clásicos -pasado- y ciudades futuristas -futuro-. Parecía que ciertas características directamente relacionadas con cómo se han etiquetado las imágenes que entrenan a estos sistemas, asociaban una determinada serie de imágenes al concepto nostalgy, relacionándolo con vehículos antiguos, generando representaciones en las que estos eran los protagonistas. Por otro lado, las asociaciones que el sistema devolvía al concepto de future parecían más predecibles, adoptando la forma de ciudades futuristas más o menos convencionales. Al introducir las dos palabras juntas, aparecían mezclados los vehículos clásicos sobre fondos de ciudades futuristas. La alumna contó que encontrarse este campo representativo asociado a la nostalgia, le causó asombro y perplejidad, y no encontraba ninguna relación con lo que de forma consciente e inconsciente asociaba al concepto. Tampoco representaba las intenciones de sus ideas iniciales que, desde su punto de vista y experiencia, podrían ser relacionados con este concepto.
En la reflexión pública y comentada de este hecho, se destacó que es asombroso -y alarmante- que la nostalgia se asocie a estos objetos -los coches antiguos- en vez de, por ejemplo, a ecosistemas intactos, a glaciares antes de derretirse, ríos impolutos o especies animales antes de extinguirse. Esto parece hablarnos de la ‘ideología subyacente’ en el acto de etiquetar, que sin duda nos parece asociado a un pensamiento masculino, blanco, occidental y ahistórico (Zylinska, 2020, p. 115). El sistema, en este caso, no parecía dejar lugar a las ideas nuevas, sorprendentes y valiosas que excedieran las ideas preconcebidas de su programador, pues reproducían exactamente éstas.
Pero Celia continuó buscando para poder sentirse interpelada por las imágenes, y su búsqueda le condujo a otro lugar semántico y representativo que en un principio no contemplaba. Con estas nuevas referencias de trabajo y buceando entre los álbumes de las fotografías familiares, descubrió imágenes que narraban la relación, desconocida para ella, de su familia con vehículos clásicos: coches y motos antiguas, incluso con el proceso de invención, por parte de su abuelo, de un vehículo que nunca se llegó a terminar.
Figura 3. Imágenes familiares descubiertas por Celia después de trabajar con los sistemas IA. Colección privada.

Se encontró de bruces con la figura un abuelo inventor de coches antiguos, lo que convirtió a las imágenes obtenidas por las IA en alegorías de una búsqueda por hacer, induciendo así una creatividad transformadora. A partir de este descubrimiento, decidió incorporar estas imágenes familiares a una selección generada por los sistemas IA para componer esos espacios que en el enunciado del proyecto se solicitaban: espacios subjetivos y que ella había elegido. En definitiva: un espacio que refleja la nostalgia de un futuro que no conocemos. En la discusión final propiciada por este proyecto, se tomó la propuesta de esta alumna como “alegoría de una de nuestras relaciones posibles” con la IA. Convinimos que es necesario trabajar con el sistema, que representa un futuro que no conocemos, para poder insertarlo en nuestros procesos de trabajo.
Figura 4. González Cáceres, C. (2023). Aspecto final de algunas de las imágenes generadas para el proyecto.

Mario Klingemann, artista que trabaja con IA, explica: “Hay muchas maneras diferentes de introducir datos en el programa y yo paso mucho tiempo experimentando con los ajustes y alterando el algoritmo hasta que siento que he creado una obra que es mía” (Fernandez Nespral, 2022).
En el caso relatado, a diferencia del propio Klingemann, que aclara que no toca ni un solo píxel fuera de los sistemas de IA, Celia trabajó y compuso a partir del álbum familiar y las imágenes generadas, hasta que sintió, también, que esas imágenes resultantes eran suyas. ¿No es lo que despiertan en nosotras lo que importa?, ¿lo que ponen en funcionamiento y en consecuencia el uso que los y las artistas hacen de ello? ¿Puede estar su auténtico valor en inducir esa creatividad transformativa? ¿Acaso no es la creatividad algo que se remodela? ¿No emerge en cada época el arte como resultado de las herramientas a disposición del artista?
La artista Ian Cheng, que trabaja en su obra con conceptos y sistemas basados en IA, afirma que
el arte puede desempeñar un papel en la mejora de la respuesta inconsciente que tenemos a la complejidad… El arte vivo y dinámico puede ser el punto de partida para una cultura futura que pueda metabolizar y desenvolverse mejor en el cambio” (Alanes, 2022).
Esta afirmación nos plantea otra pregunta: ¿podemos sentirnos aludidos, conmovidos, por un sistema que nos devuelve una visión del mundo tan parcial, ideológica y políticamente sesgada? Para poder reflejar otras epistemologías basadas en redes de relaciones que se extienden a los animales y plantas, viento y rocas, montañas y océanos como dicen Jason E. Lewis, Noelani Arista, Archer Pechawis y Suzane Kite en el ensayo Making kin with the machines se sugiere considerar el
círculo de relaciones” extendido que incluye a los parientes no humanos, desde los servidores de la red a perros robot, hasta inteligencias artificiales (IA) débiles y, eventualmente, fuertes, que pueblan cada vez más nuestra biosfera computacional. Al hacer que las epistemologías indígenas se relacionen con la “cuestión de la IA”, esperamos que se abran nuevas líneas de discusión que puedan escapar de las visiones más convencionales (Lewis, J.E. et al., 2018),
4.1. Otras posibilidades de relación con las IA
Para escapar de las limitaciones del etiquetado y poder así reflejar otras epistemologías, algunos artistas trabajan con sistemas de IA basados en GAN: Generative Adversarial Networks (Panopticon, s.f.). Son algoritmos que permiten generar datos nuevos similares a aquellos con los que han sido entrenados, y podrían compararse al mimetismo en la biología evolutiva. El artista Refik Anadol (2023), trabaja con sistemas GAN porque manifiesta no sentirse atraído por el procedimiento de etiquetado de los Diffusion Models ni por la imitación de la realidad, sino por soñar o especular cuál puede ser una visualización de la imaginación de las máquinas. Su obra Unsupervised, parte de su proyecto Machine Alucinations, ha tomado como punto de partida todos los metadatos de los archivos del MoMa, en forma de 138.000 imágenes. El resultado, expuesto en el mismo museo, (Anadol, 2023), es una instalación formada por un conjunto de imágenes y formas abstractas generativas en continuo movimiento que resultan de este método de entrenamiento no supervisado.
La artista británica Anna Ridler, interesada en los procesos de manipulación de lo material involucrados en la creación artística, utiliza GAN para crear sus obras, tomando como punto de partida dibujos hechos por ella, (Ridler, 2017) o un archivo de conchas recogido a orillas del Támesis, para su obra Shell Record (Ridler, 2021). En ambos casos, utiliza programas de aprendizaje automático que permiten entrenar al sistema con sus propias bases de datos -dibujos en el primer caso y fotografías de las conchas recogidas en el segundo-. Al tener muchos menos datos, permiten al propio artista su introducción manual para el entrenamiento, eludiendo la problemática de la caja negra del etiquetado y la asociación imagen-texto.
Estos son solo un par de ejemplos de formas de IA que participan del concepto de inteligencia basada en la “investigación atenta” surgida de las relaciones del ser humano con todo lo no humano que nos rodea. En definitiva, procesos que permitan poder obtener nuevas formas de experimentación para ver “lo otro”; otras maneras de abordar y crear nuestros entornos, entendidos como sistemas bio-geo- tecnológicos complejos.
Conclusiones
En el contexto de una asignatura de introducción a las Tecnologías Digitales aplicadas a la creación artística, hemos realizado una práctica en dos grupos de alrededor de 30 alumnos cada uno, utilizando inteligencias artificiales Generativas basadas en redes neuronales, concretamente del tipo modelos de difusión [Diffusion models], por ser los sistemas más accesibles y de más fácil y rápido manejo. Su utilización se ha encuadrado en el marco teórico de las tecnologías que utilizan las bases de datos culturales como forma simbólica, previamente trabajado con otras herramientas. Mediante la práctica, hemos identificado el problema fundamental del aprendizaje supervisado, basado en el etiquetado de imágenes y textos, que nunca es neutral y que se realiza en base a los datos introducidos por aquella persona que entrena el sistema, dando como resultado imágenes como la que encabeza este artículo. Además, Chat GPT nos ha ayudado a identificar otro problema fundamental, que es que quien etiqueta considera, por el contrario, que sí existe una manera objetiva de describir lo que vemos y que sobre esa presunta objetividad se construyen los modelos de aprendizaje supervisado. Categorizar y etiquetar es un proceso que ilustra la ideología, cultura y creencias de quien etiqueta, y por tanto una forma de política.
El alumnado, ante los resultados, ha lamentado la opacidad de los sistemas utilizados y ha desplegado estrategias para sentirse interpelado por las imágenes obtenidas, como afinar la búsqueda con sucesivas entradas de texto, haciendo referencia al estilo, color o iluminación, introduciendo en las IA imágenes propias para generar a partir de ellas nuevos resultados, o componiendo y utilizando procesos de postproducción. A pesar de las limitaciones encontradas, hemos convenido que su uso permite inducir procesos de creatividad transformadora. Una utilización continuada y consecutiva del sistema, nos ha permitido trasladarnos a lugares semánticos nuevos e insospechados, impulsando nuevas búsquedas y remodelando nuestra manera de enfrentarnos a un proceso creativo. Además, ha permitido extraer múltiples significados a partir del uso generalizado de las bases de datos como forma cultural y simbólica.
Después de esta práctica, se mostró al alumnado otras maneras de relacionarse con las IA, como las que desarrollan los artistas arriba mencionados. Muchos de ellos mostraron la intención de indagar en el uso de las GAN para poder utilizar sus propias bases de datos. Deseamos ver, en un futuro próximo, a los propios artistas entrenar de forma sencilla y accesible sus propios sistemas, como los anteriormente citados, o quizás tener la capacidad de utilizar de otra manera la relación entre las palabras y las imágenes, del modo que lo hace, por ejemplo, la propia poesía o la poesía visual.
Podríamos así, por ejemplo, obtener el dibujo global de un lugar determinado en un preciso momento visto desde una perspectiva situada, es decir, sin esa presunta objetividad que se presupone a la base de estos sistemas. Se podrían tener en cuenta los procesos o sistemas vivos que lo componen en un momento determinado: desde el sustrato geológico hasta los sistemas atmosféricos, hídricos, animales, plantas involucradas y también el hombre como una parte más de esa base de datos que subyace en ese sistema de relaciones.
Referencias bibliográficas
Alanes, A. M. (14 de octubre,2022). Can Ai Unlock the Unconscious? Right Click Save. https://qrcd.org/3jSH
Alija, A. (4 de enero, 2023). Dall-E: NLP Y IA Sobre Imágenes. Datos Gobierno de España. https://qrcd.org/3jSI
Anadol, R. (2023). Unsupervised. MoMa. https://qrcd.org/3jSK
Art Breede. (2019). Artbreeder [AI Art Generator]. https://qrcd.org/3jSL
Broussard, M. (2019). Artificial Unintelligence. How computers misunderstand the world. The MIT Press.
Cowan, S. (14 marzo, 2023). How to see like a machine. How to see series. MoMa. https://qrcd.org/3jSM
Crawford, K. y Paglen, T. (Septiembre, 2019). Excavating AI: The Politics of Training Sets for Machine Learning. https://qrcd.org/3jSN
Dayma, B. (2021-2022). DALL·E mini by craiyon.com on Hugging Face. [AI Art Generator]. https://qrcd.org/3jSO
Deepai. (2023). Deep AI Image Generator. [AI Image Generator]. https://qrcd.org/3jSP
Derrida, J. (1995). Espectros de Marx. Editorial Trotta.
Didi Huberman, G. (2010). Atlas. ¿Cómo llevar el mundo a cuestas? Museo Reina Sofía y TF Editores, Madrid.
Fernandez Nespral, M. P. (4 de noviembre, 2022). La primera portada creada con inteligencia artificial. El correo. https://qrcd.org/3jSQ
Fisher, M. (2012). ‘What Is Hauntology?’ Film Quarterly, 66, (1), 16–24. https://doi.org/10.1525/fq.2012.66.1.16
Foucault, M. (1989). Las palabras y las cosas. Una arqueología de las ciencias humanas. Siglo XXI Editores.
Foucault, M. (1981). Esto no es una pipa. Anagrama.
García, C. (Noviembre, 2022). Proyecto 2. https://qrcd.org/3jST
Huyghe, P. (Octubre, 2018). UUmwelt. Serpentine Gallery. https://qrcd.org/3jSU
ImageNet. (2021). ImageNet. [Image Dataset]. https://qrcd.org/3jSV
Kremer, A. (5 de octubre, 2022). “Is Dall-e a Genius? - Notes - e-Flux.” e- Flux. https://qrcd.org/3jSW
Lewis, J. E. et al. (2018). Making Kin with the Machines. Journal of Design and Science. https://doi.org/10.21428/bfafd97b
Manovich, L. (1998). Database as a symbolic form. https://qrcd.org/3jSX
Manovich, L. y Arielli E. (2023). AI Images and Generative Media. En Artificial Aesthetics: A Critical Guide to AI, Media and Design. https://qrcd.org/3jSY
Midjourney. (2023). Midjourney. [AI Art Generator]. https://qrcd.org/3jSZ
Mordvintsev, A. (2015) Deep Dream Generator [AI Art Generator]. https://qrcd.org/3jSa
Night Café Creator. (2019). Night Café. [AI Art Generator, AI Art Maker]. https://qrcd.org/3jSb
Oneyras. (2019). Keras. [Biblioteca de redes neuronales]. https://qrcd.org/3jSc
OpenAI. (2023). ChatGPT (9 de enero 2023) [Large language model]. https://qrcd.org/3jSd
OpenAI. (2023). DALL·E 2. [AI Art Generator]. https://qrcd.org/3jSe
Panofsky, E. (2003). La perspectiva como forma simbólica (11.ª ed.). Tusquets Editores.
Panopticon. (s.f.). What is Generative Adversarial Networks (GAN) Art? https://qrcd.org/3jSf
Replicate. (2023). Pixray/text2image. [AI Art Generator]. https://qrcd.org/3jSg
Paglen T. (Septiembre, 2019). From Apple to Anomaly. Barbican. https://qrcd.org/3jSh
Ridler, A. (2021). The Shell Record. https://qrcd.org/3jSi
Staryai. (2022). Starryai. [AI Art Generator App]. https://qrcd.org/3jSj
Wombo. (2022). Dream by Wombo. [AI Art Generator App]. https://qrcd.org/3jSk.
Zylinska, J. (2020). AI Art. Machine Visions and Warped Dreams. Open Humanity Press, London. https://qrcd.org/3jSl
BIO

Concha García González es artista multimedia, investigadora y docente en el departamento de Dibujo y Grabado de la Facultad de Bellas Artes de la UCM. Como artista, su trabajo se centra en la investigación y cuestionamiento de asunciones comunes sobre el espacio, público y privado: cómo se construye, cómo se oculta e invisibiliza, los bienes que lo configuran y su accesibilidad, con un acercamiento transdisciplinar.
Utiliza para ello el sonido y técnicas variadas con la finalidad de introducir la dimensión temporal y cinemática en la imagen: animación de dibujos, animación 2d y 3d e integración en imagen real. Trabaja con un enfoque acusmático del material sonoro, entendiendo el sonido como modelador y generador de identidades y contextos, así como expresión de sistemas de producción de espacio. Utiliza estrategias conceptuales como recontextualización, descomposición y recomposición de imágenes, ambientes y paisajes sonoros, con un enfoque centrado en la agencia de lo material. Desde un punto de vista teórico, investiga las condiciones de transformación de las asunciones sobre espacio real y la creación de espacios simbólicos, explorando campos semánticos ambiguos, inestables, efímeros, transitorios y en constante metamorfosis. mariac50@ucm.es
_______________________________
1 El inglés como idioma oficial de entrenamiento merecería una reflexión añadida que excede el ámbito de este artículo.
2 “Pipe” puede traducirse como tubería, acepción que parece la preferida por DALL.E 2, pero también manguera, pipa, cachimba, flauta, gaita, tubo.
3 Estos datasets son: (1) Conceptual Captions de Google (2) Los pares de texto e imagen de Wikipedia y (3) Un subconjunto filtrado de YFCC100M.
4 En su traducción al inglés al hacer nuestras preguntas.
5 Una de nuestras preguntas iniciales y que motivan esta investigación. (Véase la pág. 3).
6 Otra de nuestras preguntas iniciales. (Véase la pág.3).